



Key takeaways
• Low latency streaming is a solved problem — sub-second, at mass scale, once you pick the right protocol. WebRTC and the new MoQ (Media over QUIC) deliver glass-to-glass under 500 ms; LL-HLS and CMAF chunked sit at 2–5 seconds; classic HLS at 15–30 seconds.
• Architecture matters more than protocol. A cascaded SFU tree (master + edge) is what carries WebRTC from 100 to 100,000 viewers; an LL-HLS-only setup will not get you under 2 seconds no matter how it is tuned.
• The cost gap is real. LL-HLS via CDN is ~$30 per 1,000 viewer-hours; pure WebRTC SFU is closer to $5–10 per 1,000 viewer-hours at scale. Hybrid (WHIP ingest plus LL-HLS egress) cuts the bill 50–70% while keeping the interactive tier sub-second.
• MoQ is the next chapter. Cloudflare runs a production MoQ relay across 330+ cities; the IETF transport draft hit draft-18 (May 2026) and is nearing Working Group Last Call; expect mainstream adoption in 2026–2027 to push interactive streaming to 200–300 ms.
• Latency choices are revenue choices. Sub-3-second live sports retains viewers 2–3x longer than 7–9 second delays; sub-250 ms video-and-odds synchronisation lifts live-betting volumes 25%; auction houses see 20% more bids when video is interactive.
Why Fora Soft wrote this playbook
Fora Soft has been shipping live video products since 2005 — 250+ projects across real-time video, streaming and AI. Low latency streaming at mass scale started as a single-product challenge for us — WorldCast Live, a platform that streams HD concerts to thousands of viewers with audience-and-performer interaction in real time — and has since become a recurring requirement on our roster: live shopping (Sprii), real-time multilingual streaming (VOLO), enterprise video conferencing (ProVideoMeeting), and the broader real-time video stack on BrainCert.
This playbook collapses what we have learned across those products — and delivered through our video streaming development team — into a single decision framework. The numbers are pulled from public sources (Cloudflare engineering blog, Mux pricing, AWS IVS docs, the IETF MoQ working group, Apple LL-HLS specifications, the Bitmovin Video Developer report). The architecture patterns are battle-tested. Skim the key takeaways for the headline, jump to the protocol comparison for the trade-off you came for, or jump to section 13 for the five-question decision framework.
Building a live streaming product and need sub-second latency at scale?
Book a 30-minute scoping call with our streaming lead. We will sanity-check your protocol choice, fan-out architecture, and CDN strategy against your specific viewer profile.
The latency taxonomy — and why “low” is not the same as “interactive”
Latency in live streaming is glass-to-glass: the time between a photon hitting the encoder’s camera and a photon leaving the viewer’s screen. Marketing teams use it loosely; engineering teams need to be precise. The industry has converged on four tiers.
| Tier | Glass-to-glass | Use cases | Default protocol |
|---|---|---|---|
| Interactive | < 400 ms | Live betting, auctions, telemedicine, video calling | WebRTC, MoQ, AWS IVS Real-Time |
| Low | 1–3 s | Sports, live shopping, gaming, esports | LL-HLS, LL-DASH, CMAF chunked, MoQ |
| Near-real-time | 3–6 s | Concerts, news, conferences | CMAF chunked, SRT |
| Standard | 10–30 s | Music streams, archives, broadcast TV simulcast | HLS, DASH, RTMP |
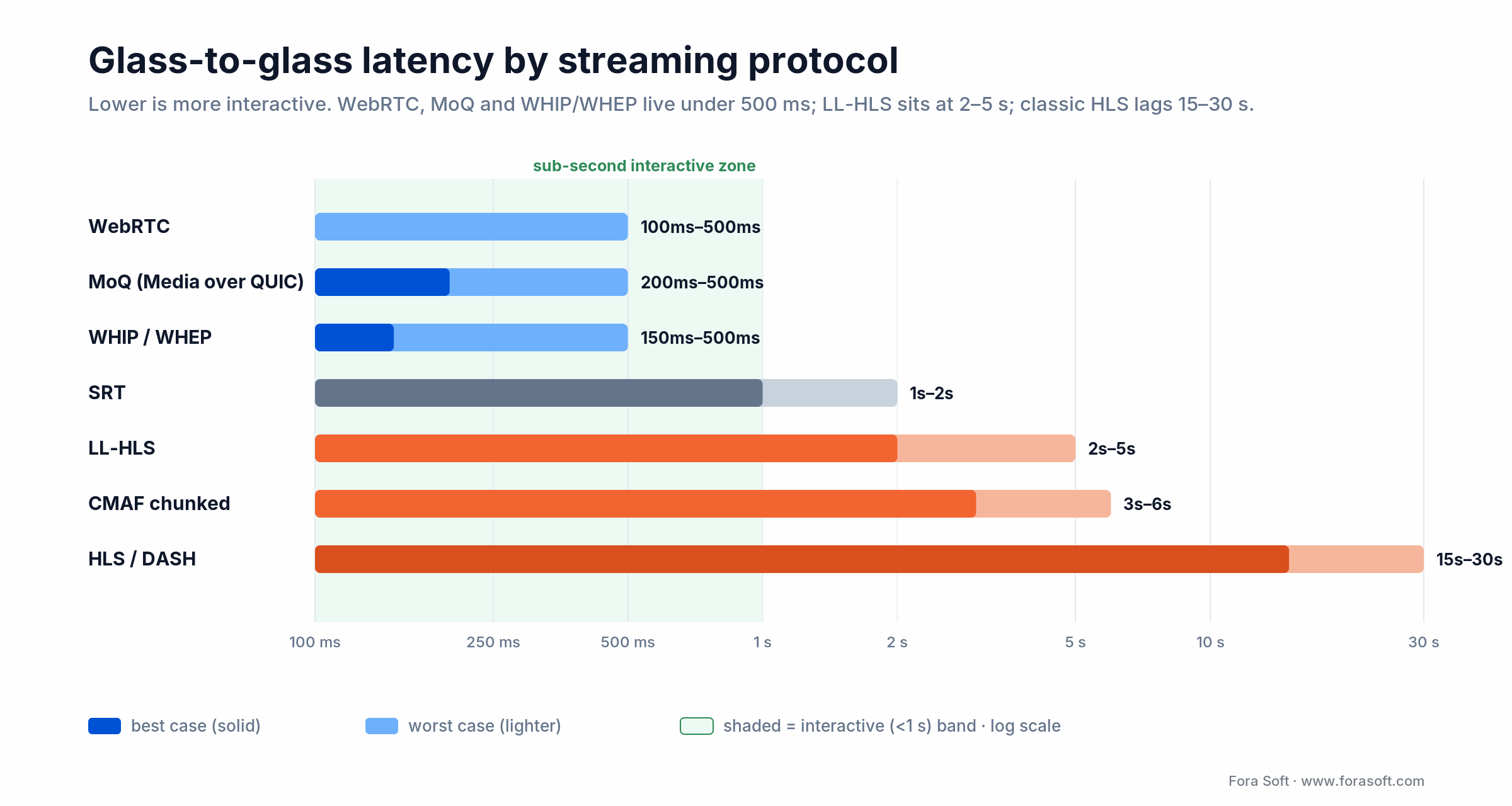
Figure 1. Where each protocol lands on the glass-to-glass latency scale — only WebRTC, MoQ and WHIP/WHEP clear the sub-second bar.
Picking a tier is a product choice, not a technical preference. A live concert can survive at 3 seconds; a live auction collapses at 1.5 seconds. Map the use case to the tier first, then choose the protocol.
Why sub-second latency moves real revenue
A second of latency is the difference between a feature and a product category. Six places where the number shows up directly in revenue.
1. Live sports retention. iGameMedia and Dolby OptiView data: viewers stay 2–3x longer on sub-3-second feeds than 7–9-second feeds. The neighbour-shouts-GOAL problem is brutal — once a viewer learns the local pub is ahead of the stream, they switch off.
2. Live betting. Sub-250 ms synchronisation of video and odds drives ~25% uplift in betting volume per public industry estimates. Micro-betting (next ball, next play) is impossible above one second.
3. Live auctions. Sub-second auction house feeds report ~20% more bids and ~25% more remote participation versus comparable mid-latency feeds. Bid-and-confirm cycles fail when delays exceed the auctioneer’s gavel. If you’re building one, our guide to live auction software covers the bid engine, anti-sniping, and latency budget in depth.
4. Interactive concerts and live shopping. Real-time chat, reactions, polls and Q&A only work below ~1 second. Above that, the comment thread reads like reading the news after it happened.
5. Telemedicine. Sub-300 ms is a clinical requirement for examination video; outside that range, the patient cannot read the doctor’s face fast enough to feel listened to.
6. Esports and game streaming. Twitch’s LL-HLS rollout and the rise of WebRTC streamers (Kick, YouTube’s low-latency mode) are direct responses to spoiler-by-chat — viewers will not tolerate a 6-second feed when chat is real-time.
Protocol comparison: WebRTC, MoQ, LL-HLS, CMAF, SRT, WHIP/WHEP
Six protocols matter in 2026. The table below is the cheat sheet we hand junior engineers on day one of a streaming engagement.
| Protocol | Latency | Scale ceiling | Reach for it when |
|---|---|---|---|
| WebRTC | 100–500 ms | 10k+ via cascaded SFU | Two-way interaction is core (calling, auctions, betting). |
| MoQ (Media over QUIC) | 200–500 ms | 100k+ via relay network | You want sub-second at WebRTC scale, plus CDN-style fan-out. |
| WHIP / WHEP | < 500 ms | 5k–100k | You want WebRTC ingest/playback over plain HTTP without custom signaling. |
| SRT | 1–2 s | Point-to-point | Contribution feeds (camera-to-cloud), broadcast pipelines. |
| LL-HLS | 2–5 s | 100k+ via CDN cache | Cost-sensitive mass distribution; one-way streams. |
| CMAF chunked | 3–6 s | 100k+ via CDN cache | Cross-platform standard playback (DASH + HLS) with chunk transfer. |
A note on classic RTMP: it is dead for delivery in 2026 and dying for ingest as WHIP matures. Keep it only where legacy encoders demand it.
Reach for LL-HLS when: the stream is one-way, 2–5 s latency is acceptable, and cost per viewer-hour has to stay near $0.01 — it rides ordinary CDN cache, so it scales to 100k+ viewers cheaply.
WebRTC at scale: SFU mesh and the cascaded tree
Vanilla WebRTC handles a 1:1 call beautifully and falls over at 50 viewers. The reason is the math: peer-to-peer mesh requires N×(N-1)/2 connections, every encoder uploads N times, every viewer renders N feeds. The fix is a Selective Forwarding Unit (SFU) that ingests one publisher stream and forwards it to every subscriber.
A single SFU node tops out at roughly 500–5,000 concurrent subscribers depending on bitrate and CPU. Past that, you cascade: a master SFU receives the publisher feed, edge SFUs subscribe to the master and re-fan-out to their own viewer pool. WCL’s original architecture used a tree of Master and Edge Kurento nodes; modern equivalents (LiveKit, mediasoup, Janus, ion-sfu) follow the same pattern.

Figure 2. The cascaded SFU tree: a master SFU feeds edge SFUs, each re-fanning ~500 viewers, so WebRTC scales without a peer-to-peer mesh.
Three knobs make the difference between this architecture surviving and collapsing.
Simulcast. The publisher uploads three quality layers (e.g., 180p / 360p / 720p). The SFU picks the right layer per subscriber. Dropping a viewer from 720p to 360p when their bandwidth dips keeps the stream alive without freezing the whole room.
SVC (scalable video coding). One stream, multiple temporal/spatial layers, less encoder overhead than simulcast. AV1 SVC is the modern target.
TURN scaling. 10–15% of viewers will be behind symmetric NATs and need a TURN relay. Provision TURN bandwidth at 1.5× expected publisher bitrate × viewer count behind NAT — underprovisioned TURN is the #1 cause of “live stream stalled” tickets.
Reach for a cascaded WebRTC SFU when: two-way interaction is the core of the product (calling, auctions, betting) and you need sub-500 ms — size the master for the first ~500 viewers and add one edge node per additional ~500.
MoQ (Media over QUIC) — the next protocol generation
MoQ — Media over QUIC — is the IETF working group’s answer to the “sub-second at CDN scale” problem. It rides on top of QUIC directly (or via WebTransport), uses a relay topology that maps cleanly to existing CDN infrastructure, and avoids the per-viewer TCP-stream overhead of HLS by sharing chunks across subscribers at the relay.
Three reasons MoQ matters now and not in 2028.
Production deployments are live. Cloudflare runs MoQ relays across 330+ cities on its existing edge, and NAB 2026 saw 11 interoperating MoQ implementations demoed side by side. Meta, Google and the major streaming platforms are all contributing.
Specification stability. The IETF MoQ transport draft reached draft-18 (May 2026) and is approaching Working Group Last Call. The wire format has stabilised, so anything you build now will not need a painful rewrite before the final RFC.
Architectural fit. Unlike WebRTC, MoQ does not require an SFU per region; the relay topology scales like a CDN. Unlike LL-HLS, it does not pay the segmentation latency tax. We ship MoQ-ready streaming products today through our custom MoQ / QUIC development practice.
Reach for MoQ when: you need WebRTC-class latency for a one-to-many or few-to-many stream and your viewer count is in the tens of thousands or higher. Use Cloudflare’s relay or roll your own with one of the open-source implementations (moqt-go, moq-rs).
Curious whether MoQ fits your roadmap?
We have shipped early MoQ pilots and run production WebRTC stacks with cascaded SFUs. A 30-minute call narrows the choice to one or two architectures specific to your viewer profile.
WHIP and WHEP: WebRTC ingest and egress over plain HTTP
WHIP and WHEP are the two small protocols that finally make WebRTC as easy to wire up as RTMP. Both replace the bespoke, hand-rolled signaling that every WebRTC stack used to ship with a single HTTP request. If sub-second latency is the goal, they are how the stream gets in and out.
WHIP for ingest. WHIP (WebRTC-HTTP Ingestion Protocol) became RFC 9725 in March 2025, so it is frozen and safe to build on. One HTTP POST negotiates the whole WebRTC session, which is why OBS, Cloudflare, AWS IVS and Mux all speak it without custom glue. It is the modern replacement for RTMP contribution — same “point an encoder at a URL” simplicity, none of the multi-second latency tax.
WHEP for playback. WHEP does the mirror image for egress: an HTTP request pulls a WebRTC stream out of a media server. It is still an IETF Internet-Draft (latest text August 2025, not yet an RFC), but it is already interoperable across the major players and fine to run in production today. Our WHEP egress explainer walks the handshake step by step, and our WHIP and WHEP vs RTMP guide covers migrating a legacy pipeline off RTMP.
Reach for WHIP/WHEP when: you want WebRTC-grade sub-second ingest or playback but do not want to build and maintain a signaling layer. Standardise on WHIP for contribution now; add WHEP for playback wherever your clients support it.
Hybrid architecture: WebRTC interactive + LL-HLS mass
Most production streaming products today — live shopping, interactive concerts, esports — are not pure WebRTC or pure LL-HLS. They are hybrids. The interactive tier (10–200 active participants who can talk back, ask questions, place bids) runs on WebRTC; the mass passive tier (everyone else) runs on LL-HLS via CDN. The transcoder bridges the two.
The economics are the reason. Pure WebRTC at 10,000 concurrent viewers can run $5,000–$10,000 per hour in SFU and TURN cost. The same audience served via LL-HLS through a CDN sits closer to $300–$500 per hour. A hybrid architecture pays the WebRTC premium only for the small interactive tier and uses cheaper, slightly higher-latency delivery for the rest.
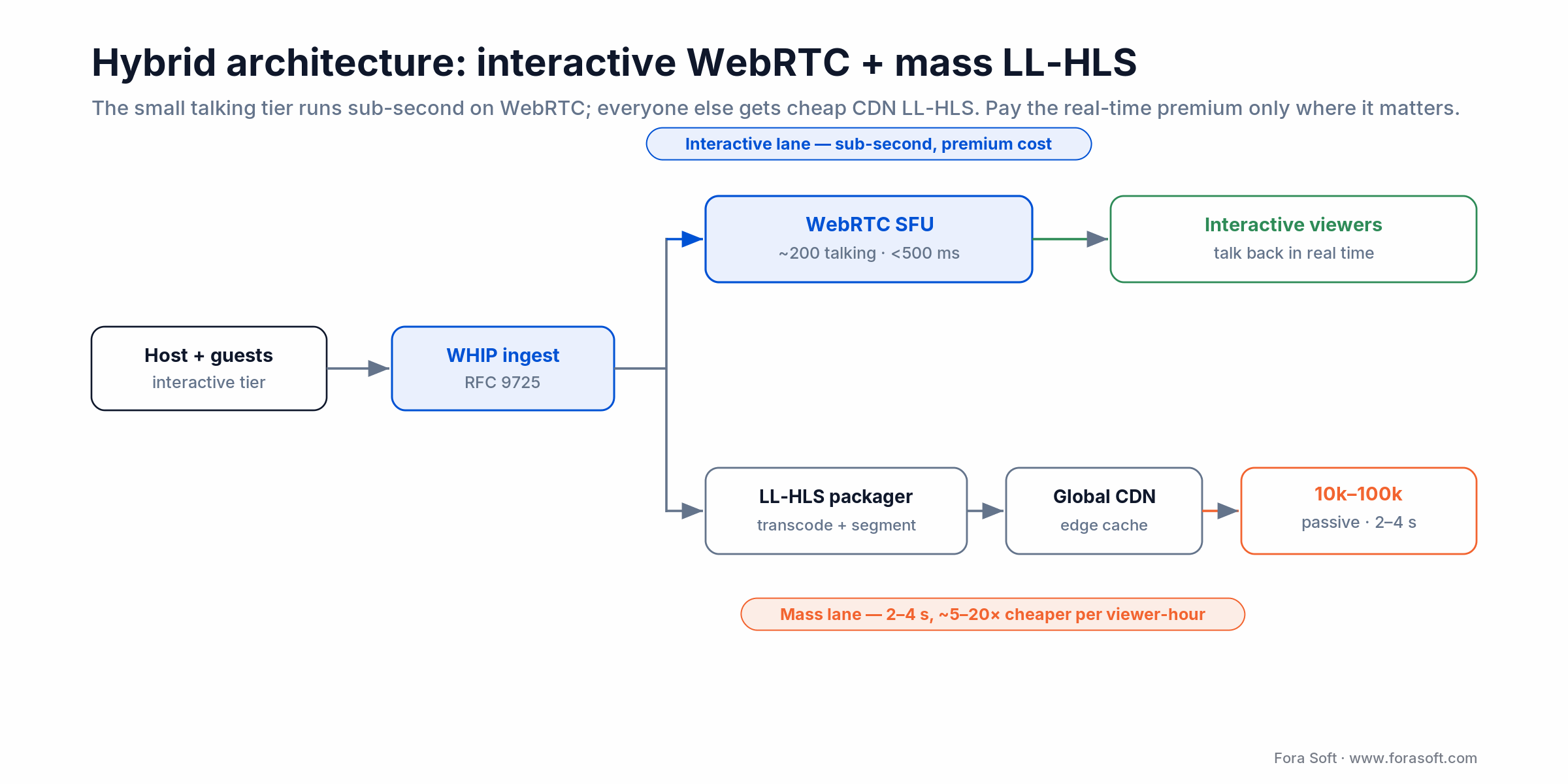
Figure 3. A hybrid split: pay for sub-second WebRTC only for the small talking tier; serve the mass audience cheaply over LL-HLS and a CDN.
The trade-off is that the passive tier sees the stream 2–4 seconds later than the interactive tier. For most product designs that is acceptable; the active participants do not see the chat from the passive viewers in real time anyway.
Reach for a hybrid WebRTC + LL-HLS split when: your talking tier is under ~200 and your passive tier is over ~5,000. It cuts infrastructure cost 50–70% versus pure WebRTC while keeping the interactive tier sub-second. See the LL-HLS deep-dive for the mass-tier tuning.
Cost economics in 2026 (per 1,000 viewer-hours)
The numbers below are pulled from the public price sheets of Cloudflare Stream, AWS IVS, Mux Real-Time, and indicative LiveKit pricing. They normalise to one thousand viewer-hours so you can compare across protocols.
| Stack | Latency | Cost / 1k viewer-hr | Notes |
|---|---|---|---|
| Mux LL-HLS | ~4 s | ~$33 | Encode plus delivery; indicative blended rate at typical live bitrates. |
| Cloudflare Stream | < 1 s (WebRTC) | $1–5 (delivery only) | $1 per 1k delivered minutes; storage extra. |
| AWS IVS Real-Time | < 300 ms | ~$50–100 | RTMPS or WHIP ingest; custom enterprise pricing for large rooms. |
| Self-hosted WebRTC SFU | 100–500 ms | ~$5–10 + bandwidth | Bandwidth is the dominant cost at scale. |
| Hybrid WebRTC + LL-HLS | < 500 ms / 2–4 s | ~$10–20 (blended) | Best for >5k passive viewers with a small interactive tier. |
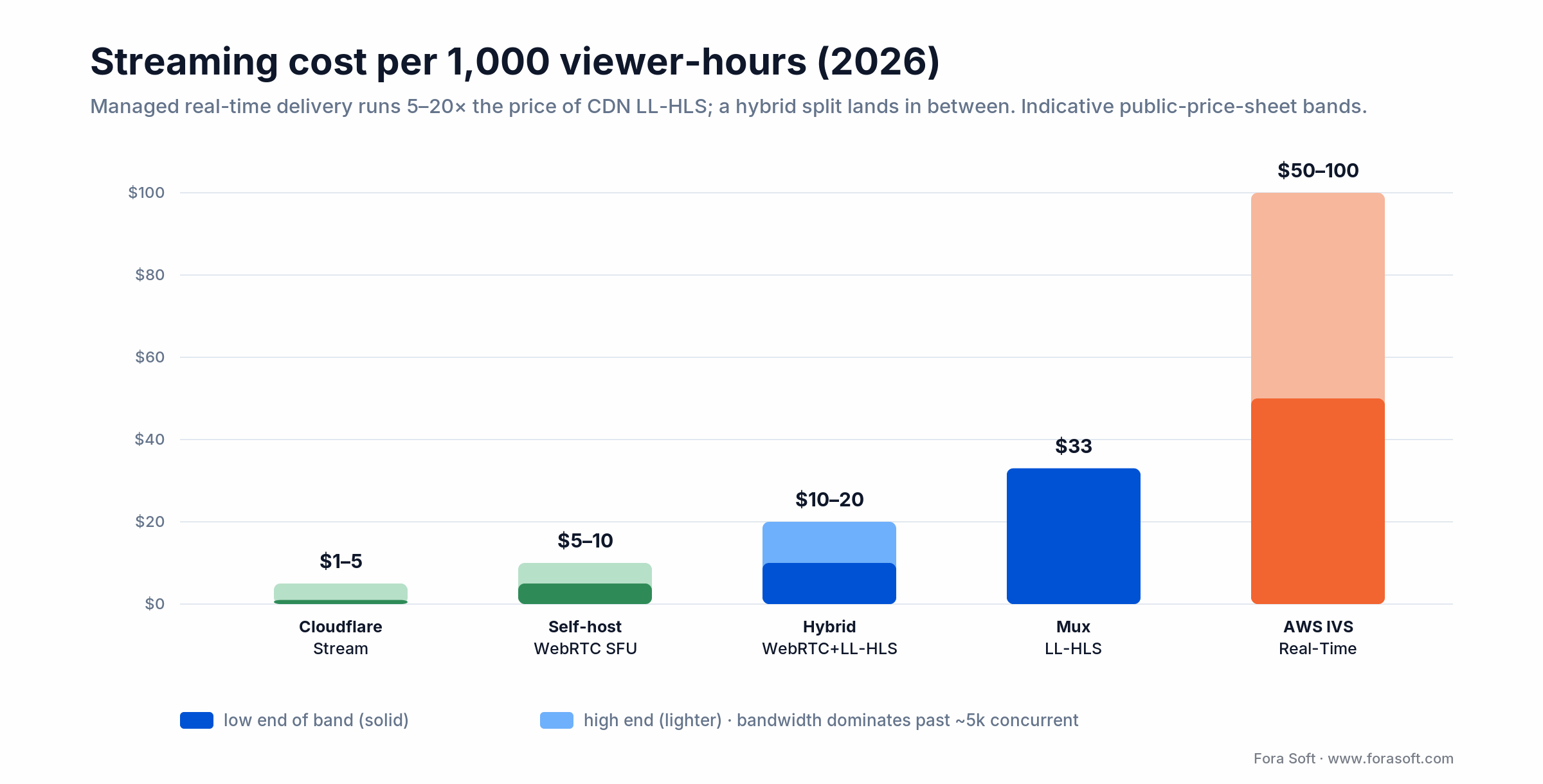
Figure 4. Indicative 2026 cost per 1,000 viewer-hours — managed real-time delivery runs 5–20× the price of CDN LL-HLS.
Bandwidth is the dominant variable at scale. A 720p stream at 2 Mbps to 10,000 concurrent viewers is 20 Gbps of egress. CDN bandwidth pricing dominates the bill once you cross ~5,000 concurrent viewers.
Encoder settings that move latency by hundreds of ms
Even with the right protocol, the encoder can blow the latency budget. Five settings to audit on day one.
1. B-frames off. B-frames depend on future frames and add encoder buffering. For interactive streams, set bframes=0; the bitrate cost is small (~5%) and the latency cost is huge (50–200 ms saved).
2. Short GOP / I-frame interval. 2-second GOP for LL-HLS; 1-second or sub-second for interactive. Shorter GOPs let segments close faster and players start faster.
3. Codec choice. H.264 has the lowest encode latency and the widest device support; HEVC and AV1 give 30–50% bandwidth savings at the cost of 50–100 ms more encoding latency. AV1 SVC is the future for WebRTC; legacy devices still need H.264 fallback.
4. Tune for zero-latency, not film. x264 tune=zerolatency preset=veryfast sacrifices some bitrate efficiency for buffer-free encoding. Necessary for interactive workloads, optional for sub-3-second LL-HLS.
5. Hardware acceleration. NVIDIA NVENC, Intel Quick Sync, Apple VideoToolbox encode 5–10× faster than software at the price of slightly higher bitrate at the same quality. For a real-time pipeline, hardware encode is mandatory above 1080p.
Network resilience: surviving the lossy last mile
Sub-second latency is fragile. WebRTC starts to break above ~5% packet loss; LL-HLS handles loss better at the cost of latency. Four mechanisms keep streams alive on real networks.
FEC (forward error correction). Send 10–20% redundant data so receivers can reconstruct lost packets without retransmission. Trades bandwidth for latency stability.
NACK and selective retransmit. The receiver requests specific lost packets; the sender retransmits only what is missing. Effective up to ~150 ms RTT.
Jitter buffer tuning. Aggressive buffers (50–100 ms) for interactive, conservative buffers (200–500 ms) for one-way. The buffer is what absorbs microbursts of network instability.
Bandwidth estimation. Google’s gcc and BBR-based congestion control. Modern WebRTC stacks ship this by default; the trap is custom builds (older Janus, older Pion) that lag the spec by 12–18 months.
Mini case: WorldCast Live shipping sub-second to 1,000+ concurrent
WorldCast Live streams HD concerts in sub-second latency to thousands of viewers across multiple embed sites. The product requirement was unforgiving: viewers and performers had to talk back and forth in real time during a live concert; latency above 1 second made Q&A unworkable.
The architecture: WebRTC end-to-end, multichannel audio (5 channels for stage mix), bitrate raised to 1.5 Mbps for true HD, increased audio sampling for lossless music quality, and a cascaded Kurento tree (Master + Edge nodes). Master handles the first 500 viewers; each Edge adds another 500. The tree extends as the audience grows.
Outcome: glass-to-glass latency under 700 ms for the talking tier, packet loss tolerated up to 4%, audio quality validated with PESQ scores in the 4.0+ range. The first stable build took 3.5 weeks; the engineering effort would compress further today with our agentic-engineering practice. The architecture has since carried multi-thousand-viewer concerts without a meaningful rebuild.
Five pitfalls we see in low-latency streaming projects
1. Picking the wrong protocol for the use case. Trying to hit 500 ms with LL-HLS is a fool’s errand; trying to hit 100k viewers with vanilla WebRTC will bankrupt you. Map use case to tier to protocol — in that order.
2. Underprovisioned TURN. 10–15% of viewers will need TURN relay; provisioning at 1.5× expected NAT bandwidth is the floor. Underprovisioned TURN is the top cause of “why does the stream stall for some users” tickets.
3. Missing simulcast. A single 720p stream sent to a viewer on 3G freezes the room. Always simulcast at least three layers (180p / 360p / 720p) and let the SFU pick.
4. B-frames left on. Every interactive WebRTC stream we have audited that had B-frames enabled was paying 100–200 ms of avoidable latency. Audit first, then optimise.
5. CDN configured for VOD, not live. Stale-while-revalidate, long cache TTLs, missing chunked-transfer support, no LL-HLS partial-segment cache configuration. The default CDN profile is wrong for live; always configure live-specific edge rules.
A decision framework — choose the right stack in five questions
Q1. What is the maximum acceptable glass-to-glass latency? Under 500 ms → WebRTC or MoQ. 1–3 s → LL-HLS. 3–6 s → CMAF chunked. Above 6 s → standard HLS / DASH.
Q2. How many concurrent viewers do you expect peak? Under 1k → single SFU. 1k–10k → cascaded SFU or hybrid. 10k+ → MoQ relay or hybrid WebRTC+LL-HLS+CDN.
Q3. How many viewers actually need to talk back? Under 200 → WebRTC interactive tier sized for that. Above 200 → hybrid architecture is the only way the math works.
Q4. What is your target unit cost per viewer-hour? Under $0.01 → LL-HLS via CDN is the only option. $0.01–$0.10 → hybrid or managed WebRTC service. Above $0.10 → pure WebRTC SFU is fine.
Q5. Is latency a hard product requirement (betting, auctions) or a polish item (concerts, news)? Hard → over-invest now in cascaded SFU and FEC. Polish → ship LL-HLS first, upgrade selectively.

Figure 5. Five questions that pick the stack — latency target and viewer count choose the protocol; the talking-tier size decides pure vs hybrid.
When NOT to chase sub-second latency
Three cases where the cost outweighs the benefit. First, music or talk-only streams where the audience is passive and listens, not interacts. The standard 6-second TV-style delay is fine and saves significant infrastructure spend.
Second, archival workflows or long-tail VOD that catches up after the live moment. Use HLS or DASH; reach for low-latency only on the live edge.
Third, products in clear MVP mode where infrastructure cost is the dominant constraint. Ship LL-HLS for the first 12 months; upgrade to a hybrid stack once you have validated demand and the unit economics support it.
KPIs: what to measure on every live stream
Quality KPIs. Glass-to-glass latency p50 and p95 (measured via SMPTE timecode or NTP-stamped audio tones). Packet loss rate (target under 2%). Freeze ratio (frozen frame seconds divided by stream seconds, target under 1%). VMAF or PESQ scores for video and audio.
Business KPIs. Average watch time (compare against a 6-second-latency baseline). Chat-to-stream sync delta (target under 1 second). Bid completion rate for auctions; play-action latency for live betting; question-to-answer time for interactive Q&A.
Reliability KPIs. SFU CPU utilisation (target under 70%). TURN bandwidth utilisation (target under 60% with autoscale). Edge node failure-recovery time (target under 5 seconds). Cost per concurrent viewer-hour, tracked per channel weekly.
Adjacent topics worth a deeper read
Four companion reads round out the streaming-product picture.
Architecture deep-dive. The custom video conferencing architecture guide covers the SFU, MCU and P2P trade-offs in more detail.
Reliability foundation. Sub-second latency is moot if the stream crashes. See our crash-proof software guide for SLOs, error budgets and DORA metrics applied to streaming.
Hiring & teams. Real-time streaming is a specialist hire; our LiveKit hiring guide covers skills, rates and interview questions for the WebRTC and SFU specialists you will need.
Mobile foundations. The Android foreground service guide covers the lifecycle scaffolding mobile streaming clients need so the OS does not kill them mid-stream.
FAQ
What is the lowest latency achievable for live streaming today?
In production, around 100–200 ms glass-to-glass with WebRTC on healthy networks within a single region. AWS IVS Real-Time advertises sub-300 ms; Cloudflare’s WebRTC delivery sits below 1 second to global audiences. Beyond about 100 ms you hit speed-of-light limits across continents.
Can LL-HLS deliver sub-second latency?
No. Apple’s LL-HLS spec targets 2–5 seconds via partial segments and preload hints. Anyone advertising sub-1-second LL-HLS is either using a non-standard variant or measuring from the wrong point. For sub-second latency, use WebRTC or MoQ.
How many concurrent viewers can a single WebRTC SFU handle?
Roughly 500–5,000 depending on bitrate, codec, and CPU. A high-end LiveKit or mediasoup node tuned for 720p H.264 SFU forwarding can hit 5,000 subscribers; for higher bitrates or more publishers, plan to cascade across multiple nodes.
Is MoQ ready for production in 2026?
Yes for early adopters. Cloudflare runs a production MoQ relay across 330+ cities; the IETF transport draft reached draft-18 (May 2026), is nearing Working Group Last Call, and had 11 vendors interoperating at NAB 2026, with implementations in Go and Rust. Mainstream adoption is 2026–2027. We are happy to scope an MoQ pilot if your roadmap supports it.
When should we use a hybrid WebRTC + LL-HLS architecture?
Whenever the active interactive tier is small (under ~200 talking participants) and the passive viewer tier is large (5,000+). The hybrid pays the WebRTC premium only for the interactive tier and uses cheap CDN delivery for the rest, cutting infrastructure cost 50–70% versus pure WebRTC.
What is WHIP and why is it replacing RTMP for ingest?
WHIP (RFC 9725, published March 2025) is a simple HTTP-based protocol for publishing a WebRTC stream into a server. It eliminates the bespoke signaling layers most WebRTC stacks ship and is supported by OBS, Cloudflare, AWS IVS, Mux and most modern streaming infrastructure. WHEP is its playback counterpart. Together they make WebRTC ingest as plug-and-play as RTMP without the latency tax.
How much does a sub-second mass streaming product cost to build?
A scoped MVP with a hybrid WebRTC + LL-HLS architecture typically lands in a 6–10 week engineering window on a healthy team. Our agentic-engineering practice compresses the typical timeline. Infrastructure cost depends entirely on viewer counts; see section 08 for the per-viewer-hour ranges. For a scoped estimate against your specific use case, a 30-minute call is usually enough.
What metrics should we monitor on a live stream?
Glass-to-glass latency p50/p95, packet loss percentage, freeze ratio (frozen seconds / total seconds), VMAF or PESQ quality scores, SFU CPU utilisation, TURN bandwidth utilisation, and cost per concurrent viewer-hour. See section 15 for the full KPI list.
What to read next
Architecture
Custom video conferencing architecture in 2026
P2P, SFU, MCU — the architecture trade-offs that underpin every low-latency streaming product.
Media servers
What is Kurento?
The open-source WebRTC media server that powered the original WorldCast Live tree.
Hiring
How to hire LiveKit developers in 2026
Skills, rates and interview questions for the WebRTC and SFU specialists you will need.
Reliability
Building reliable, crash-proof software in 2026
SLOs and error budgets applied to live streaming — sub-second latency means little if the stream crashes.
Mobile
Foreground services and deep links on Android 14
The lifecycle scaffolding mobile streaming clients need so the OS does not kill them mid-stream.
Ready to ship sub-second streaming to thousands of viewers?
Low latency streaming at mass scale is a solved problem in 2026. The two paths are a cascaded WebRTC SFU tree (proven, expensive, sub-500 ms) and the new MoQ relay model (CDN-class scale at WebRTC-class latency, cost still being shaped). For most products today, a hybrid WebRTC interactive tier plus LL-HLS mass tier delivers the right balance of cost and experience.
If you want a second pair of eyes on your streaming architecture, or a team that has shipped sub-second streaming products since the WebRTC 1.0 era, we are a 30-minute call away. We will return a written architecture memo with cost estimates inside a week.
Need streaming under one second to thousands of viewers?
Tell us about your viewer profile and budget. We will return an architecture memo with protocol choice, fan-out plan, and cost per viewer-hour inside a week.









