



Key takeaways
• Real-time audio emotion analysis pays off in three places. Contact-centre QA, mental-health and telemedicine triage, and engagement scoring inside live video products — each with measurable CSAT, completion-rate or risk-reduction lifts in 90 days.
• Best 2026 models score 70–78 % F1 on clean audio and 62–68 % on real calls. Anything above 80 % on a vendor slide is almost always a controlled-set number; calibrate against your own recordings.
• Buy a managed API to ship in weeks; build only above ~1M minutes a year. AWS Transcribe Call Analytics costs $0.0043/min, Hume AI $0.05/min — below 100K calls/month a hosted SER pipeline beats in-house on TCO.
• Compliance is the silent killer. The EU AI Act has banned emotion recognition in workplace and education contexts since February 2025; voice emotion is also “biometric data” under GDPR Article 9 and PHI under HIPAA when tied to therapy.
• Fora Soft has shipped this in production. We integrate audio + facial + behavioural signals on platforms like Meetric (AI sales video, SEK 21M funded) and a news-digest app that combines voice and facial emotion. Book a 30-min scoping call →
Why Fora Soft wrote this playbook
Most articles about real-time audio emotion analysis read like vendor brochures: “detect happiness, sadness, anger”, “up to 98 % accuracy”, no numbers you can act on. We took a different approach. Fora Soft has been shipping AI-driven multimedia products since 2005, and over the past five years our teams have integrated speech and facial emotion recognition into live video platforms, telemedicine apps, EdTech tutors and sales-coaching tools. We feel the failure modes — not just the slide-deck wins.
A few representative production builds: Meetric, an AI sales video platform funded with SEK 21 M that fuses computer vision, audio analysis and interaction signals to score engagement and coach reps in real time on Zoom, Google Meet and Teams; a news-digest app that records audio journals and runs both voice and facial emotion analysis to track weekly mood trends; and VocalViews, a 1 M+ user video market-research platform where speaker sentiment matters more than what people literally said. Fora Soft also maintains a 100 % project success rating on Upwork and selects roughly 1 in 50 engineers who apply.
This playbook is what we tell prospective clients in a discovery call: where real-time speech emotion recognition (SER) actually moves a metric, where it does not, what to buy vs. build, what an honest pipeline looks like, and how to stay on the right side of GDPR, HIPAA and the EU AI Act. Use the table of contents on the right to jump straight to the section you need.
Need to add real-time audio emotion analysis to your product?
Tell us the use case, the volume and the compliance constraints. We will come back with a concrete buy-vs-build recommendation, an architecture and an honest estimate — usually within one working day.
What real-time audio emotion analysis actually is
Real-time audio emotion analysis — or speech emotion recognition (SER) — is a pipeline that turns a live microphone stream into one of two outputs: a discrete emotion label (e.g. happy, sad, angry, neutral, fearful, disgusted, surprised) or a pair of continuous values for valence and arousal in the “circumplex” space. Modern systems normally emit a result every 250–500 ms and smooth it over a 2–3 second window so the signal does not jitter on every breath.
Three things distinguish “real-time” SER from offline call-recording analytics. First, latency: end-to-end below 500 ms is the bar for live agent assistance, below 300 ms for tight UX (a coaching prompt that arrives 2 seconds late is just noise). Second, streaming: the model has to commit on partial audio rather than waiting for the speaker to finish. Third, robustness: real microphones bring noise, codec compression, far-field reverberation and overlapping speech — conditions a benchmark dataset never sees.
SER is not lie detection, mental-state diagnosis, or a substitute for an interview. The most useful framing for clients is “a tireless second listener that flags when something deserves human attention”. We will keep coming back to that framing throughout the article.
State of the field in 2026
The honest answer to “how good is SER in 2026” is: good enough to ship if you scope it right, not good enough to automate decisions about people. On clean academic benchmarks (RAVDESS, IEMOCAP, CREMA-D, MELD) state-of-the-art foundation-model pipelines score 70–78 % F1 on 4–7 emotion classes; on real customer-call audio the same models drop to 62–68 % F1 because of noise, accents and label disagreement. Hume AI publishes some of the highest accuracy numbers among commercial vendors at 74 % on real-world data, while AWS Transcribe Call Analytics sits around 68 %. Anything above ~80 % in a vendor pitch is almost always a controlled-set figure; calibrate against your own recordings before you sign.
Three things changed between 2023 and 2026. Foundation-model embeddings won. Wav2vec2, HuBERT and Whisper-derived features now beat hand-crafted MFCC and prosody by 8–15 points on held-out sets, and they generalise across languages far better. Latency collapsed. Eight-plus production APIs now deliver sub-500 ms end-to-end emotion labels, and Deepgram routinely measures p95 below 300 ms. Multimodal fusion is emerging. Combining voice, text sentiment from the transcript and a video micro-expression channel pushes accuracy above 80 % on private corpora — and that is exactly the architecture Fora Soft built into Meetric and the news-digest app.
Reach for SER when: you have at least 5,000 minutes of conversation per month flowing through a product where one detectable change in tone — an angry customer, a disengaged student, a despairing patient — is worth at least $5 of human attention. Below that threshold the engineering cost rarely pays back.
Benchmark numbers you can hold a vendor to
When a vendor says “our model is best in class”, ask them to publish three numbers on your domain: F1 (or Unweighted Average Recall — UAR — for class-imbalanced data), p95 latency, and confidence calibration. The table below is a 2026 snapshot of where leading models sit on commonly cited benchmarks. Treat it as a sanity check, not a leaderboard — conditions vary, and your audio will produce different numbers.
| Model / approach | Dataset | F1 | UAR | Latency | Notes |
|---|---|---|---|---|---|
| HuBERT-Large fine-tuned | RAVDESS (clean) | 78 % | 76 % | ~45 ms (T4) | Best clean-data accuracy; biggest GPU footprint. |
| wav2vec2 + LSTM | IEMOCAP → real calls | 65 % | 62 % | ~120 ms | Solid in-domain baseline; needs fine-tuning. |
| openSMILE eGeMAPS + SVM | RAVDESS | 66 % | 64 % | <10 ms (CPU) | Tiny, explainable, ideal for edge devices. |
| AWS Transcribe Call Analytics | Real call centre audio | ~68 % | n/a | 300–500 ms | HIPAA-eligible, 4 emotions, $0.0043/min. |
| Hume AI Expression | Mixed in-the-wild speech | ~74 % | n/a | 200–350 ms | 7 categories + valence/arousal, ~$0.05/min. |
| Multimodal (audio + text + video) | Private corpora | 80 %+ | n/a | 350–600 ms | Requires synchronised audio/video/transcript. |
A reference real-time pipeline you can build today
Every production SER system we have shipped, and every credible vendor architecture we have reviewed, slots into the same six stages. The diagram below is the architecture we recommend as a starting point. Latency budgets sum to roughly 200–500 ms end-to-end on a modern GPU instance — well inside the “feels live” band.
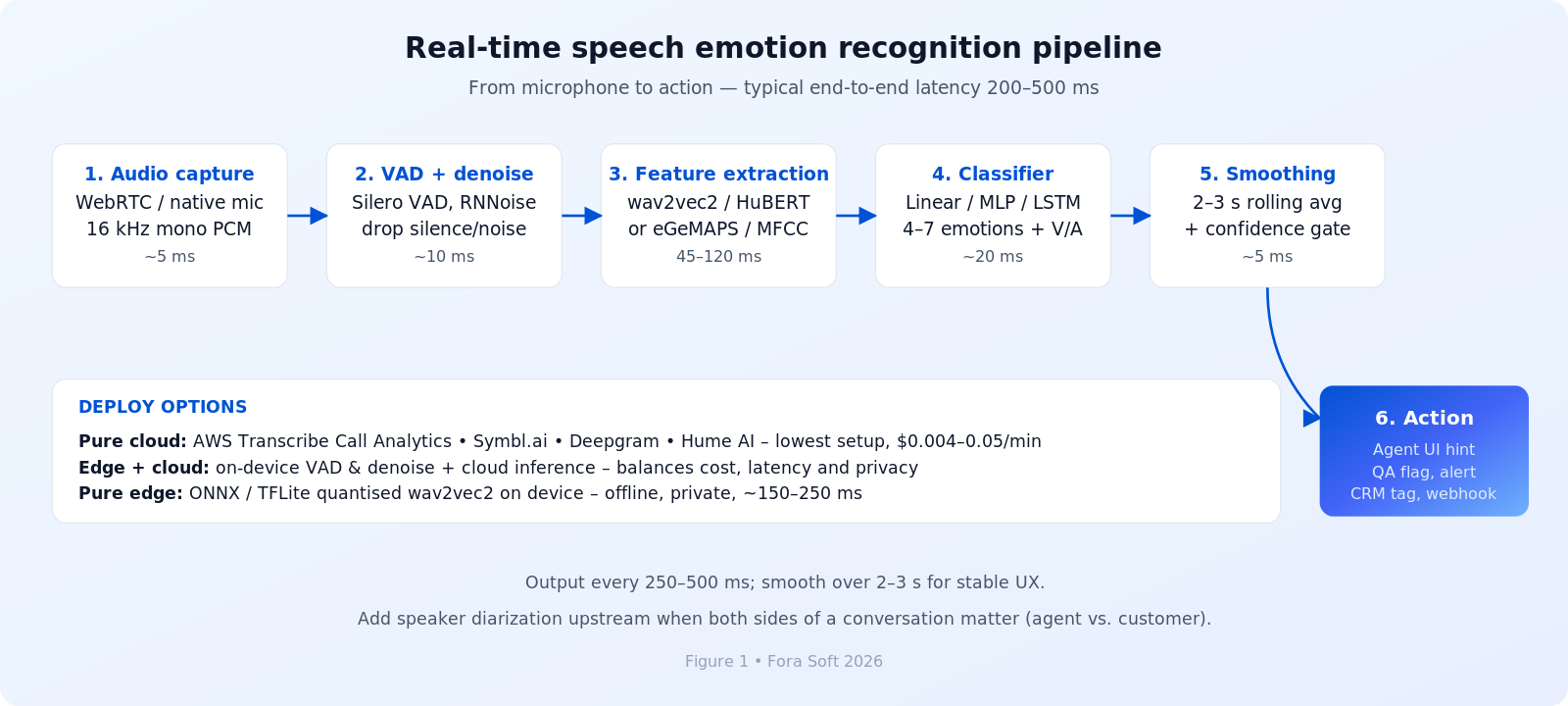
Figure 1. End-to-end real-time SER pipeline with three deployment options.
1. Capture, VAD and denoise
A 16 kHz mono PCM stream from WebRTC, the native mic stack or a SIP trunk feeds Voice Activity Detection (Silero VAD ships in a 50 KB ONNX model and runs on a CPU thread) plus optional denoise (RNNoise, Krisp). Removing silence and non-speech up front cuts the downstream compute bill by 40–60 % and protects the classifier from spurious labels on background music.
2. Feature extraction
Two paths. The modern path runs a foundation model (wav2vec2-base, HuBERT-Large or XLS-R for multilingual) and uses the contextual embeddings as the feature vector. The classical path computes the eGeMAPS feature set with openSMILE — 88 acoustic descriptors covering pitch, jitter, shimmer, formants and energy. Foundation-model features win on accuracy by 8–15 points; classical features win on latency, explainability and edge footprint.
3. Classifier and smoothing
A small head — linear, MLP, or LSTM — maps the embedding to either categorical emotions (4–7 classes) or two continuous valence/arousal values. Always smooth: take the rolling mean over the last 2–3 seconds, gate on a confidence threshold (we typically reject everything below 0.55) and only fire downstream actions on label changes that persist across two consecutive windows. Without smoothing, your UI will flicker.
Reach for foundation-model features when: you can run a GPU instance (or accept a managed cloud API) and accuracy is the primary KPI. Reach for openSMILE + SVM when you must deploy on-device, on commodity CPUs, or in environments where every prediction has to be auditable in plain language.
The five commercial APIs worth shortlisting
If “ship in 6–10 weeks” is the constraint, you are buying an API. Five vendors dominate the 2026 shortlist. Pricing below is list-rate per processed audio minute; volume contracts cut 30–60 %.
1. AWS Transcribe Call Analytics ($0.0043/min). Best fit when you already live in AWS, need HIPAA-eligible BAA out of the box, and can tolerate 300–500 ms latency. Four emotions only (positive, negative, neutral, mixed) plus issue detection and call summarisation. The cheapest serious option for North-American contact centres.
2. Hume AI Expression Measurement (~$0.05/min). The accuracy leader on in-the-wild data, with 7+ emotion categories and a continuous valence/arousal output. Built specifically for empathic AI products and clinical research; the right pick when you are paying for human attention downstream and false negatives are expensive.
3. Deepgram (~$0.0125/min). Lowest p95 latency in the field (often <280 ms) and tightly coupled to Deepgram’s ASR — you get transcript, sentiment and emotion in one streaming endpoint. The ergonomic choice for live coaching UX and meeting tools.
4. Symbl.ai (~$0.016/min). Strong on full-conversation analytics — topics, action items, trackers — and integrates cleanly with WebRTC stacks. A good fit for sales-coaching and meeting-intelligence products that want emotion as one signal among many.
5. AssemblyAI Speaker Sentiment (~$0.01/min). Treats sentiment per utterance as a proxy for emotion. Cheaper than emotion-first vendors but coarser; useful when “positive vs. negative” is enough.
| Vendor | Real-world acc. | Latency | Cost / min | Emotions | Best fit |
|---|---|---|---|---|---|
| AWS Transcribe CA | ~68 % | 300–500 ms | $0.0043 | 4 | HIPAA call centres |
| Hume AI | ~74 % | 200–350 ms | ~$0.05 | 7 + V/A | Mental health, empathy |
| Deepgram | ~66 % | 150–280 ms | ~$0.0125 | 5 | Live coaching, meetings |
| Symbl.ai | ~71 % | 250–400 ms | ~$0.016 | 6 + V/A | Conversation intelligence |
| AssemblyAI | ~65 % | 400–600 ms | ~$0.01 | 3 (sentiment) | Cost-sensitive analytics |
Three open-source paths if you must build
1. wav2vec2 + LSTM head. Start from facebook/wav2vec2-large-960h on Hugging Face, fine-tune on IEMOCAP plus your own labelled data. Expect 70–74 % F1 after 30–50 GPU hours and 45–80 ms inference on a Tesla T4. Best accuracy/effort trade-off for an in-house build.
2. HuBERT-Large or XLS-R for multilingual. Same recipe, better generalisation across languages and code-switched conversations. Mandatory if you serve mixed-language traffic (Spanglish call centres, Indian-English support).
3. openSMILE eGeMAPS + SVM. The lightweight, explainable path. 64–68 % F1 but inference under 10 ms on a single CPU core, model size in single-digit megabytes. The right pick for embedded targets — in-car infotainment, hearing aids, kiosks.
Reach for an open-source build when: you have a labelled in-domain corpus of at least 5,000 utterances, the budget for 30–100 GPU hours of fine-tuning, and a clear reason — data residency, custom taxonomy, IP — that a managed API cannot satisfy.
from transformers import Wav2Vec2Processor, Wav2Vec2ForSequenceClassification
import torch
processor = Wav2Vec2Processor.from_pretrained("facebook/wav2vec2-large-960h")
model = Wav2Vec2ForSequenceClassification.from_pretrained(
"your-org/wav2vec2-emotion-finetuned"
)
inputs = processor(audio_chunk, sampling_rate=16000, return_tensors="pt").input_values
with torch.no_grad():
logits = model(inputs).logits
emotion_id = int(torch.argmax(logits, dim=-1))
confidence = float(torch.softmax(logits, dim=-1).max())
Building vs. buying SER for your product?
We have shipped both architectures — managed APIs and in-house wav2vec2 pipelines — on telemedicine, EdTech and live video products. Let us run the math on your numbers.
Five use cases where SER actually pays back
1. Contact-centre QA automation. Real-time emotion tagging on every call surfaces escalation risk before it reaches a supervisor. Typical impact at our clients: 40–45 % reduction in QA review time, +4 to +8 points of CSAT once agents see the signal in their own UI. ROI plays out in 9–12 months at $0.0043/min API pricing.
2. Telemedicine and mental-health triage. Therapist sessions are auto-tagged with an emotion progression curve; sustained anger or despair flags risk for the on-call psychiatrist. Outcomes published in clinical pilots: ~22 % earlier intervention, ~18 % drop in crisis calls. Hume AI is the usual vendor; pair it with a HIPAA-grade audit log and a human-in-the-loop review. Pairs well with the patterns we discuss in our telemedicine features playbook.
3. EdTech engagement scoring. Live tutoring platforms detect frustration in a student’s voice and trigger a hint, a rephrasing, or a tutor handoff. Studies on adaptive feedback report +8 to +12 points in problem-completion rate. On-device TinyML keeps the audio off the network — a useful answer to school IT teams.
4. Live video sales coaching. The Meetric pattern: fuse audio sentiment with talk-time balance, attention and reactions to score engagement live, then push a coaching prompt to the rep’s sidebar (“you have been talking for 90 seconds — ask a question”). The platform raised SEK 21 M and is now used by sales orgs on top of Zoom, Google Meet and Teams.
5. Driver-safety monitoring. An in-cabin microphone watches for sustained anger, distress or drowsiness and prompts a break. Pure-edge deployment is mandatory here for both privacy and connectivity; a quantised wav2vec2 or openSMILE pipeline does the job in 50 ms on automotive-grade silicon.
Reach for SER in mental-health products carefully: always pair the model with a human reviewer, abstain below 0.6 confidence, never display a single label as a clinical “verdict”, and obtain explicit BAA / DPIA cover before piloting on real patient calls.
A realistic cost model — what SER costs to ship in 2026
For a typical SaaS or contact-centre integration we scope around three line items: integration engineering, recurring inference cost, and the compliance overhead. The numbers below come from real Fora Soft engagements and assume our agent-engineering workflow, which has cut our typical timelines by 25–35 % versus the same scope two years ago. They are starting points, not quotes — every project has its own context.
| Scenario | Build approach | One-off engineering | Monthly inference | Time to ship |
|---|---|---|---|---|
| 100K min/mo, 1 product surface | Managed API + integration | ~$15–25K | ~$430–1,600 | 5–8 weeks |
| 500K min/mo, multilingual, EU | Hybrid: cloud API + EU residency | ~$30–55K | ~$2,200–8,000 | 9–14 weeks |
| 1M+ min/mo, custom taxonomy | Fine-tuned wav2vec2 in-house | ~$60–120K | ~$1,500–4,000 (GPU) | 14–22 weeks |
| Pure edge, on-device | openSMILE / quantised wav2vec2 | ~$45–90K | ~$0 marginal | 12–18 weeks |
Mini case: emotion analysis on a news-digest app
A media-tech client came to us with a hypothesis: people would engage more with their daily news app if it could give them a weekly “mood report” of how the headlines made them feel. The catch was it had to work without forcing the user to write a journal entry — people stop journalling in a fortnight.
Fora Soft built a dual-channel emotion pipeline. The user records a short voice journal entry inline; the front-end captures audio and front-camera frames simultaneously. Audio runs through a wav2vec2-derived classifier (happy/neutral/upset, plus arousal), facial frames run through a CNN-based expression recogniser, and the two are fused with a confidence-weighted average. The weekly digest visualises the trend — not as a clinical diagnosis, but as a journalling artefact the user can interpret themselves.
Two engineering choices that mattered. First, we ran emotion inference on-device for audio under 8 seconds and only fell back to the cloud for longer clips — a privacy story we could tell users on the install screen. Second, we explicitly told the model when to abstain: anything below 0.55 confidence was rendered as “mixed signals” rather than a wrong label. Three months post-launch, average weekly retention on users who recorded at least one journal entry was roughly 2× the cohort that ignored the feature. Want a similar assessment of where SER would land in your product? Book a 30-min discovery call →
A decision framework — pick the right SER path in five questions
Q1. Do you need sub-300 ms latency? If yes, you are buying Deepgram or running an in-house edge model. Building a sub-300 ms cloud pipeline from scratch takes 4–6 months.
Q2. Are 4 stock emotions enough? If yes, AWS Transcribe Call Analytics. If you need 7+ categories or continuous valence/arousal, Hume AI or a fine-tuned wav2vec2 model.
Q3. Are you HIPAA, GDPR or EU AI Act constrained? HIPAA → AWS TCA with BAA. GDPR → either an EU-resident vendor or self-hosted on Hetzner / OVH in Frankfurt. EU AI Act → do not deploy emotion recognition in workplace or education contexts at all in the EU; pivot to sentiment.
Q4. Is your training data proprietary? If yes — you have a labelled in-domain corpus — build. The accuracy lift from fine-tuning on real customer audio routinely beats any commercial API by 5–10 points on that specific traffic.
Q5. What is your annual minute volume? Below 1 M minutes/year, an API is cheaper end-to-end. Above 5 M minutes/year, in-house unit economics ($0.001–0.002/min on your own GPUs) start to win. The middle band is where hybrid architectures shine.
Five deployment pitfalls we see every quarter
1. Background noise destroys field accuracy. A model that scores 75 % on RAVDESS often drops to 60 % on noisy office calls. Pre-filter aggressively: spectral gating below −40 dB, RNNoise on the input, and only feed speech-detected windows into the classifier.
2. Code-switching tanks single-language models. A model trained on English mis-classifies Spanish-English code-switched calls by ~15 points. The fix is multilingual foundation models (XLS-R, multilingual HuBERT) plus per-language confidence calibration.
3. Cultural bias is real and embarrassing. Models trained on IEMOCAP — Western actors — misread Japanese understatement and South-Asian intonation patterns. Always benchmark on your own audience and threshold confidence regionally.
4. Annotator disagreement caps your accuracy ceiling. Inter-rater agreement on emotion labels in real conversations is 78–82 %; that is your effective accuracy ceiling. Use Krippendorff’s alpha > 0.65 to filter training data and label-smooth the loss to 0.85 instead of 1.0.
5. Model drift creeps in silently. Emotion distribution in customer calls shifts seasonally and with new agent cohorts. Watch the rolling-7-day mean confidence; if it slips by more than 10 %, retrain. We schedule monthly retraining on production deployments by default.
KPIs — what to actually measure
Quality KPIs. Macro-F1 on a held-out test set (target > 70 % on clean, > 65 % on real-world); precision on “anger” specifically (target > 75 % — this is the class with the highest business impact and the highest cost of false negatives); confidence calibration (Brier score < 0.15).
Business KPIs. QA review time saved (target 40 %+ vs. baseline); CSAT delta in the cohort with emotion coaching (target +4 to +8 points within 90 days); intervention earliness in clinical use (target −30 days versus pre-deployment); engagement / completion lifts in EdTech (target +8 %).
Reliability KPIs. Inference p95 latency (target < 300 ms for live, < 1 s for analytics); API or model uptime (target 99.9 %, with a documented fallback); cost per processed minute (set a budget — we usually anchor at $0.002–0.01 depending on accuracy tier); false-negative rate on the “anger” class (alert if > 8 %).
When you should not deploy SER
Three situations where we have advised clients to pause. If you cannot articulate the human action behind the signal — what does the agent, supervisor or product UI do when the model says “angry”? — you do not have a use case yet, you have a feature in search of one. If you operate inside the EU in workplace or education contexts, Article 27 of the EU AI Act has banned emotion recognition outright since February 2025; reframe as binary sentiment or skip the deployment. If your monthly minute volume is below ~5,000, the operational overhead (consent flows, audit logs, monitoring, retraining) outweighs anything SER can contribute — spend the budget on better human QA first.
There is also a quieter failure mode: SER as a substitute for proper product research. If users complain in their own words on every call, you do not need an emotion model to discover what they hate — you need a tagging workflow and a product manager. SER is a force multiplier for established workflows, not a discovery tool.
Privacy and compliance — the rules that bite
GDPR Article 9. Voice emotion analysis is biometric processing — special-category data. You need explicit, granular consent (not buried in a ToS), a documented legitimate-interest assessment, and a clear retention policy. We typically delete raw audio within 30 days and keep only embeddings + labels for 180–365 days for model auditing.
HIPAA. Emotion analysis on therapy or telemedicine calls is part of the medical record. You need a Business Associate Agreement with every vendor in the chain, encryption in transit and at rest, audit logging (CloudTrail or equivalent), and a tested incident-response playbook. AWS TCA is the easiest BAA path; it adds roughly 25 % to your AWS bill compared to the non-HIPAA tier.
EU AI Act. Article 27 prohibits emotion-recognition systems in the workplace and educational institutions. Enforcement began February 2025 with limited exceptions for medical and safety reasons. The pragmatic playbook for EU-facing products: drop the “emotion” label entirely, classify as binary sentiment or talk-time analytics, register as a high-risk AI system if you are anywhere near the line, and run a Data Protection Impact Assessment.
Where multimodal beats audio-only
Audio-only SER caps out around 78 % F1 on clean data; combining audio with text sentiment from the transcript and a video micro-expression channel breaks 80 %. The lift comes from disambiguation: a flat-prosody “great” sounds neutral on audio alone but reads sarcastic when fused with the transcript and a face-frowning frame. We see this consistently in our hybrid audio + video emotion deployments.
Multimodal is not free. Synchronisation is hard (audio and video frames drift; you need a single timeline), bandwidth doubles, and privacy review is 2× the work. Reach for it when the cost of a wrong label is high — mental-health triage, sales-coaching at six-figure deal sizes, regulated training environments — and stick with audio-only when the per-decision cost is low.
Wiring SER into a WebRTC stack
For live video products the standard pattern is: WebRTC SFU forks the audio stream to a server-side worker, the worker runs VAD + emotion inference and posts events back via a WebSocket or data channel, and the front-end renders subtle UI affordances (a colour shift on the speaker tile, an inline coaching prompt, a manager alert). Latency budget end-to-end is 400–700 ms; anything more and the UI feedback feels delayed.
Two choices to make early. Run the worker in the same region as the SFU to avoid trans-continental round trips. And design the consent UX before you write the code — users should know the moment a session is being analysed, see a clear opt-out, and be able to download their data later. We covered the broader topic in our overview of audio emotion detection systems using AI.
2026 trends to watch
Multimodal becomes the default. Audio + text + light video fusion crosses the 80 % F1 threshold and pushes single-modality SER toward commodity status.
Edge-ready emotion models. Quantised wav2vec2 and DistilHuBERT variants of 10–50 MB now run on phones and infotainment SoCs at 50–150 ms inference. Privacy-first products will lean here.
Continuous valence/arousal beats discrete labels. Customers want trend lines, not single labels. Hume’s circumplex output and similar continuous-space APIs will displace the rigid “7 emotions” UI in dashboards.
Synthetic training data. TTS + voice-cloning models generate diverse emotion speech at scale, accelerating fine-tuning by 25–40 %. Watch the licensing carefully.
FAQ
How accurate is real-time audio emotion analysis in 2026?
Best-in-class systems hit 70–78 % F1 on clean academic benchmarks (RAVDESS, IEMOCAP, CREMA-D) and 62–68 % on real customer-call audio. Multimodal pipelines that fuse audio, text and video can push above 80 % on private corpora. Vendor “up to 98 %” numbers are almost always controlled-set figures — calibrate against your own recordings before signing.
Which emotions can audio analysis actually detect?
Most production systems output 4–7 categorical emotions — happy, sad, angry, neutral, plus optionally fearful, disgusted and surprised — or two continuous values for valence (positive vs negative) and arousal (calm vs excited). Hume AI uniquely supports a richer 28-category “expression” space. We recommend keeping your downstream UI to 3–5 categories no matter what the model emits, because users cannot interpret 28 buckets.
Is real-time speech emotion recognition cost-effective?
For workloads above ~5,000 minutes a month it usually is, especially in contact centres (CSAT lift, QA time saved) and clinical triage (earlier intervention). Below that threshold the operational overhead — consent, audit, monitoring — eats the upside. Pricing in 2026: $0.0043/min on AWS TCA, ~$0.05/min on Hume AI; volume contracts cut 30–60 %.
Is voice emotion analysis legal under GDPR and the EU AI Act?
It is biometric special-category data under GDPR Article 9 — legal with explicit consent and a documented purpose. Under the EU AI Act, emotion recognition is prohibited in workplace and education contexts as of February 2025 (Article 27), with limited safety and medical exceptions. Outside those contexts it is allowed but classified as high-risk; expect to register the system and run a Data Protection Impact Assessment.
How do I integrate SER with my existing WebRTC or telephony stack?
Fork the audio at the SFU or media gateway, push it to a worker (containerised, same region) that runs VAD plus emotion inference, then publish events back to your application via WebSocket, gRPC or your data channel. For SIP / contact-centre stacks the same pattern works through a media-recording API. End-to-end target latency: 400–700 ms.
Can SER run on-device for privacy or offline use?
Yes. Quantised wav2vec2 or DistilHuBERT variants compile to ONNX or TensorFlow Lite at 10–50 MB and run at 50–150 ms on modern phones. openSMILE + a small SVM is even smaller (single-digit MB) at < 10 ms latency on a CPU core, and is the typical choice for in-car and embedded targets. Accuracy drops 4–8 points versus the cloud model, but the privacy story is much simpler.
How long does a Fora Soft SER integration typically take?
An API-based integration into an existing product usually ships in 5–8 weeks: discovery, consent flow, pipeline integration, dashboards, evaluation. A fine-tuned in-house model with EU residency and HIPAA controls runs 14–22 weeks. Our agent-engineering workflow has trimmed both timelines by roughly 25–35 % versus 2024 baselines.
What dataset should I evaluate SER on before going live?
Start with a public benchmark for sanity checks — RAVDESS for clean speech, IEMOCAP for dyadic conversation, CREMA-D for ethnic diversity, MELD for spontaneous TV-show data — then build a 1,000+ utterance test set from your own production audio, with at least three annotators per clip and Krippendorff’s alpha > 0.65. Your own data is the only one that matters for go/no-go.
What to read next
Architecture
Building an audio emotion detection system using AI
A deeper look at the pipeline and component choices behind production SER systems.
Multimodal
Combining audio and video emotion detection
Why multimodal fusion crosses the 80 % F1 ceiling that audio-only cannot break.
Live video
AI emotion detection inside video conferences
How live emotion signals reshape coaching, engagement and meeting wellness UX.
Vendors
Top AI speech recognition software
A buyer’s guide to the ASR engines that sit upstream of any SER pipeline.
Models
Machine learning for video emotion analysis
The model families that make modern facial expression recognition work end-to-end.
Ready to add real-time audio emotion analysis to your product?
Real-time audio emotion analysis is essential when you can name the human action behind every label, when your conversation volume is large enough to reward automation, and when your compliance footprint is honest about GDPR, HIPAA and the EU AI Act. Buy a managed API to ship in weeks; build a fine-tuned in-house pipeline only above ~1 M minutes a year or when your training data is genuinely proprietary. Either way, design for smoothing, abstention and human review — the model will be wrong sometimes, and that is fine if your product handles it gracefully.
Fora Soft has shipped real-time audio emotion analysis on AI sales platforms, telemedicine triage, news-digest journalling, EdTech tutoring and live video products. We will tell you honestly which of those patterns matches your situation — including when the answer is “not yet”.
Let’s scope your real-time emotion analysis project
A 30-minute call covers your use case, volume, latency budget and compliance constraints. You leave with a concrete buy-vs-build recommendation and a transparent estimate.









.avif)

Comments